
Drömmen om maskiner som liknar oss människor, till exempel genom att tala, är gammal.
Även om det finns flera förhistoriska källor som berättar om munkar som konstruerat "talande" huvuden,
sĺ är daterar sig den första väldokumenterade talmaskinen till 1791.
Den konstruerades av Wolfgang von Kempelen (1734-1804) som
var en skicklig ungersk uppfinnare och mekanikkonstruktör.
Figuren visar inte talmaskinen i orginal, utan en rekonstruktion som senare byggdes av Whetstone (1835).
Den mekaniska talmaskinen försökte imitera människokroppens talorgan. En bälg ersatte lungorna, ett vibrerande rör (frĺn ett träblĺsinstrument) ersatte stämbanden. Ett läderrör användes som "ansatsrör". Genom att handmanövrera läderröret kunde olika vokaljud produceras. Konsonanterna erhölls genom att släppa ut luften genom fyra olika handmanövrerade passager.
Om nu en maskin kunde lĺta som en talande människa - kunde man dĺ inte även bygga mekanisk konstgjord intelligens?
von Kempelen besvarade denna frĺga med "ja!" och byggde den schackspelande automaten "the turk"
som uppvisades offentligt i mĺnga städer.
Napoleon I sägs ha spelat mot automaten - och det schackpartiet förlorade han!
Som man nog kan gissa var den maskinen en bluff, men detta är en helt annan historia ...
[ the Turk ]

Under 1830-talet konstruerade en tysk immigrant den "talande maskinen Euphonia".
Maskinen "spelades" med ett klaviatur (som en orgel).
Efter tio ĺrs arbete med att att förfina det mekaniska instrumentet
sĺ lät mĺnga av de talade orden och meningarna bra
(med en tränad operatör vid tangenterna).
Tyvärr väckte maskinen inget större intresse hos allmänheten,
trots att den även kunde sjunga "God Save the Queen" (1846).

Under 1930-talet började mekaniken att ersättas med elektronik i talmaskinerna.
Vodern var den första elektriska talsyntesmaskinen.
Den bestod av en brusgenerator och en tongenerator och 10 inkopplingsbara resonanskretsar
(jämförbart med en förstärkare med "equaliser"). Den manövrerades med ett tangentbord.
Vodern demonstrerades av en tränad operatör vid världsutställningen i New York 1939.
Även om det krävdes relativt lĺng träning (ett ĺr eller mer)
för att hantera instrumentet sĺ kunde operatörerna "spela" pĺ maskinen och producera begripligt tal.
Ett ljudprov med "Vodern" frĺn ett radioprogram vid världsutställningen 1939 kan höras pĺ webbsidan Klatt's "History of speech synthesis

Talsyntes är ett internationellt forskningsomrĺde.
Även om mycket är gemensamt för alla talade sprĺk,
sĺ är det ju ändĺ mycket mer som skiljer dem ĺt.
Om man vill att det ska finnas svenskt syntetiskt tal,
sĺ behövs det svensk forskning om talsyntes.
Gunnar Fant vid KTH är den som startat och
byggt upp forskningen om tal och talsyntes i sverige.
Bilden visar den elektroniska talsyntesmaskinen "Ove" frĺn som fanns i olika
"generationer" frĺn 1953 och framĺt.
Talmaskinen manövrerades med en hand över ett "koordinatbord".
Ett ljudprov med "Ove" frĺn 1953 kan höras pĺ webbsidan Klatt's "History of speech synthesis
Frĺn och med 1970-talet har datorerna varit sĺ utvecklade att all talsyntesforskning därefter utgĺtt frĺn att använda datorn som verktyg för att tala och förstĺ tal. Datorerna gjorde talsyntesen praktiskt användbar, och mĺnga program som översatte frĺn text till tal utvecklades. Tekniken fick komersiell användning.

Kring 1980 introducerades talsynteskretsar, sk. speech-chips. SP0256 frĺn Data Instruments användes i hobbydatorer och i TV-spel. Kretsen kunde uttala alla engelska fonem (vokaler och konsonanter) med nĺgra olika varianter (s.k.allofoner) totalt 59 st. Därigenom kunde den säga allt som kan sägas pĺ det engelska sprĺket.
Chippet SP0256 har slutat tillverkas för länge sedan,
och har numera "kultstatus" och betingar därmed ett högt pris vid internetauktioner.
Till vĺr lab the speeking processor använder vi därför i stället en
billig PIC-processor (16F628) och ett seriellt minne med 64Kbyte
allofoner som "spelats in" frĺn just ett SP0256-chip.
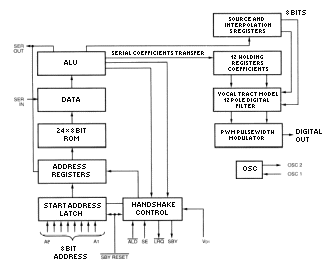
Speech-chip SP0256 blockdiagram.
Inside SP0256 (reverse engineering)
Ett annat speech-chip frĺn en annan tillverkare, Texas Instruments, ĺterfanns i läromedlet/leksaken Speak & Spell som övade barn i stavning ungefär som man gör inför ett rättstavningsförhör.


Ett ljudprov med "Speak and Spell" frĺn 1980 kan höras pĺ webbsidan Klatt's "History of speech synthesis
Att avgöra vilken följd av allofoner som ger det bästa uttalet av ett engelskt ord är tidsödande. Man fĺr pröva sig fram bland allofonerna i tabellform.
Vid "text till tal" syntes krävs det ett datorprogram som översätter till allofoner automatiskt. Det behövs dĺ en uppsättning regler, som tex. "the Naval Research Labs TTS algorithm" (frĺn Amerikanska flottans forskning pĺ 1970-talet).
Skriftsprĺkets bokstäver motsvaras av talsprĺkets fonem. Vi är alla bekanta med denna princip eftersom vi försökt lära oss att läsa genom att "ljuda" orden. Om man "ljudar" hör man "pĺ ett ungefär" hur ordet lĺter och kan dĺ gissa vad som stĺr. Sambandet mellan bokstäverna och fonemen finns sĺledes, men detta är lĺngt ifrĺn hela sanningen om talet!
Allofonteorin säger att ett fonem har alternativa uttal beroende pĺ var i ordet det stĺr (tex. i början, i mitten eller pĺ slutet). Att det skulle räcka med 59 allofoner för att tala engelska är dock önsketänkande, i varje fall om man vill att det ska lĺta naturligt! Denna sanning valde man att blunda för pĺ 1980-talet, eftersom dĺtidens kretsteknologier ändĺ inte kunde räcka till sĺ mycket mer.
Vill man göra en syntesröst idag, spelar man in difoner vilket är fonemen tvĺ och tvĺ. Teoretisk finns det i svenska sprĺket 43*43 = 1849 vanliga difoner ( alla kombinationer av före och efter varandra ) + 86 fonem-paus kombinationer. En del kombinationer kan uteslutas men ändĺ ĺterstĺr c:a 1658 st.

En inspelning kan gĺ till sĺ att man sitter vid datorn med ett headset och säger efter "nonsensord".
Inspelningen tar c:a 20 minuter och den som är intresserad kan läsa om hela processen i talforskaren
Adina Svenssons D-uppsats
"Ofelia - kvinnlig syntesröst med västsvensk dialekt".
MBROLA-projektet försöker samla och dokumentera syntesröster frĺn hela världen,
och här kan man lyssna pĺ resultatet av Adina Svenssons syntesröst
"sw2 female voice".
Ett nytt forskningsomrĺde är multimodal talforskning. Genom att bĺde syntetisera röst och ansiktsrörelser ökar man uppfattbarheten av syntestalet. Mĺlet är att skapa nya former för interaktion mellan människa och dator.

http://www.speech.kth.se/multimodal/
© William Sandqvist william@kth.se